One of the most common features in a code editor is without doubt code completion (aka auto completion). Every programmer has seen this before and an explanation is no longer necessary. Still it makes sense to recall what *exactly* code completion is supposed to do. It should provide the programmer with a list of strings that can appear at a given position in the code (usually the one where the caret is). It is also sensible to require code to be syntactically correct up to the invocation point. Otherwise it is really difficult to predict what the user wanted to write actually.
Implementing code completion is a non-trivial task and there are different approaches possible. This posting describes a way to accomplish that with relatively few core code, as I have done it in MySQL Workbench. It delivers very precise results and requires only few changes to adjust it to different languages.
Where to start?
A typical approach to implement code completion is to use a parser for a given language – after all it should have all necessary information, no? Wrong. All what a parser has is informations about lexer tokens. It can give you a list of allowed tokens at any given position (the socalled follow-set or lookahead-set). And in an error case a good parser can provide you with a list of expected tokens … well, sometimes … if there are not too many errors in the code. In fact, you cannot rely on that, as you want code completion also to work if there is no error. There is no guarantee the parser can give you that info reliably. At least not when it is backtracking to try different routes through the grammar. Additionally, what do you want with that list of tokens actually? Right, keywords come to mind. But in general the parser is not a good tool for code completion.
Now, what should a list of code completion candidates really contain? Certainly possible keywords, but that’s not all. Depending on the language for which code completion is invoked that can be all kind of object names (class identifiers, database objects, member names etc.) as well as functions, operators and many more. Nothing of all that is in the grammar or known to the parser, simply because this is domain knowledge not represented by the grammar.
Still, I tried this approach in older MySQL Workbench versions (for code completion in SQL editors). I thought by applying some heuristics (big switch statements that were used to find candidates just by looking at the last few tokens) I could quickly get the desired results. The only thing I got quickly was the realization that this will not lead to what I wanted. The code grew and grew and I constantly had to add more special cases. Nobody would be able to maintain that later, let alone not to break something when you have to add a new part.
In newer version of the application I went a totally different way, which I’m going to explain here. In the following description I will link directly to the parts in the implementation hosted on Github so that you can easily follow the explanation. The entire code completion implementation is contained in a single C++ file. Then you need the MySQL ANTLR grammar and the generated token list (which is not on Github as it is, well, generated). However it looks very much like the list of predefined tokens, which is used as kind of a template for the final list. This list contains the mapping between terminal token names and their values used in the generated parser.
Prepare your grammar
When I say the domain knowledge is not coded into your grammar then it doesn’t mean we couldn’t change that. In fact, when you look at a typical grammar you will always find rules that describe a specific detail, that is not needed for the parser as such, but useful for you as grammar author. The parser, however, will not keep these details in any way useful for code completion. But we can use the grammar to keep our domain knowledge in form of rule names that reflect specific aspects.
For instance in the MySQL language there is a part like this for table creation:
create_table_option:
ENGINE_SYMBOL EQUAL_OPERATOR? identifier
...
;
for something like: create table t ... engine = InnoDB;
You can see there’s a typical rule for specifying an identifier, which you can always find in this or a similar form in most grammars. Now let’s apply domain knowledge here:
create_table_option:
ENGINE_SYMBOL EQUAL_OPERATOR? engine_ref
...
;
engine_ref:
identifier
;
Since you know this identifier must be one of the possible engines you can easily make this explicit, which will later help a lot, as you will see. By writing your grammar like this you can put all kind of information into it that can later be used to find the right candidates. In the MySQL grammar I have such rules for all types of objects (columns, tables, schemas, engines, views, tablespaces etc.). In a more C like language you could instead use
member_name:
identifier DOT_SYMBOL identifier
;
that tells you the member of a struct or class is needed in this specific position.
Open the Treasure Chest
However, how can we use this additional information if the generated parser doesn’t keep it? For this step we need a way to make the rules available such that we can traverse them. What I did was to create a parser for ANTLR grammars to load our grammar into a data structure. That sounds more complicated as it is. The ANTLR grammar is small and so is the resulting parser. Not much overhead for the benefit. The data structure is also relatively simple. We keep all rule names from the grammar in a map so we can easily look them up. Each rule (and any block for that matter) comprises a list of alternatives. Each alternative is a sequence of tokens (terminals, i.e. keywords, or non-terminals, i.e. rules). In order to avoid deep nesting of structures all blocks (those parts within parentheses) are given an auto generated name and they are stored as own rule in the rule map (just like the regular rules).
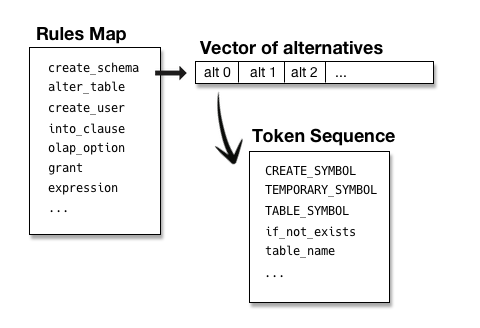
On startup the MySQL grammar file is parsed and its rules are stored in that data structure along with additional info. Since we want dynamically switchable language parts in our grammer there are sometimes semantic predicates used for an alternative. These should of course also be considered for code completion to avoid suggesting e.g. a keyword that is only allowed in a specific server version. For that also the predicates are parsed and stored as part of an alternative. In an ANTLR generated parser these predicates are written in the target language and embedded in the generated code, hence they can be compiled into binary form. In our code completion structure we cannot do that and hence have to decompose them and store e.g. the server versions as simple values we can use in comparisons. This limits predicate parsing to only a handful very specific predicate types, but that’s ok in this case.
For every token we also store its cardinality (i.e. is it optional or can it appear more than once).
Finding the Candidates
With that structure in place we can now apply a simple walk algorithm that takes the input (provided by a lexer for your language) and travels from node to node until the caret position has been found. The used scanner is a simple class that wraps the generated lexer and provides functions to jump from token to token and get informations about them (type, content, position in the source etc.).
The entire algorithm consist just of 2 (main) functions that call each other recursively. Here’s an abstract description how it works:
Begin with the start rule of your grammar and call the rule walker function.
rule walker
for each alternative
if there's a predicate and it's not matched continue with next alternative
store current input position for backtracking
try to match it with the sequence walker
record how much we consumed from input
restore position
end alternative
Jump to position of the longest match we found
end walking
sequence walker
if empty go out
for each node
if node is a terminal then match to current input token
else match rule via rule walker
if node is loop continue with it until there is no match anymore.
if matched and reached caret position then collect candidates
end node
end walking
As you can see there can be several calls to collect candidates (because of the recursive nature), if more than one path through the grammar leads to the same caret position. This is totally ok and might sometimes lead to suprising results. But you will see that everything is right, still. You may however want to limit the length of the candidates list to a usable amount to avoid overwhelming the user. One way to do this is to show the list not before the first letter has been written, so you can already filter by that.
The actual implementation is of course a bit more complex as we have to properly determine when we still successfully matched the input (interspersed with collecting actions) and when we should stop.
Once we reached the caret position we can start collecting possible candidates,
which reminds somewhat on the lookahead-set used in a parser. The
difference here is that we not only collect terminal tokens (i.e.
keywords and other simple types like numbers, operators etc.) but we can
examine which rules could follow. When we meet a rule like the
engine_ref from above we don’t follow it further (down to identifier and
ultimately the IDENTIFIER terminal), but simply push the rule name (engine_ref) to the candidates list. In order to know which rules apply here we keep a list of all those rule names that should be used as they are.
Otherwise the collection step works similar as the previous match step.
All tokens that directly follow the caret position are either put on
the candidates list or (in case of non-terminals) we follow them down to
terminal tokens or special tokens. Here we also have to make sure that
we allow tokens after the directly following ones if they are optional.
Get the Nuggets
At
the end of this match-and-collect algorithm we will have a list filled
with either keywords or rule names. Now it’s time to convert the
keywords into a readable form (e.g. from CREATE_SYMBOL to CREATE or create) and fill in object names for the rule names. In our implementation we have an object name cache that can be queried for names of a given type. So, when we have a table_ref
(which is a qualified identifier: id.id) we scan both parts using the
lexer again. Keep in mind the caret can be within such a token sequence
that makes up a parser rule, so you have to accuont for that. For
example if we see id. for an identifier with the caret
after the dot we know that id must be a schema and we want to have all
tables in it. Similarly for other references, e.g. if you find a variable_ref you ask your cache for all variables available at this position etc.
With this step our task is finished and we have a very precise list of possible candidates to show. Of course, you have to filter that list by what the user has already typed.
What’s next?
As you can see the current implementation is tailored towards MySQL and the use in MySQL Workbench. However, it’s not a difficult task to refactor the code such that we have a base class with the core functionality and derivative classes for the individual languages. In fact that is what I plan, in order to support e.g. Python in a future version of MySQL Workbench. The current version is only the first step.
If you have questions regarding the implementation don’t hesitate to contact me. I also welcome any improvement or extension for a more general use.
There is an ANTLR Google discussion group. Please join us there for discussions.