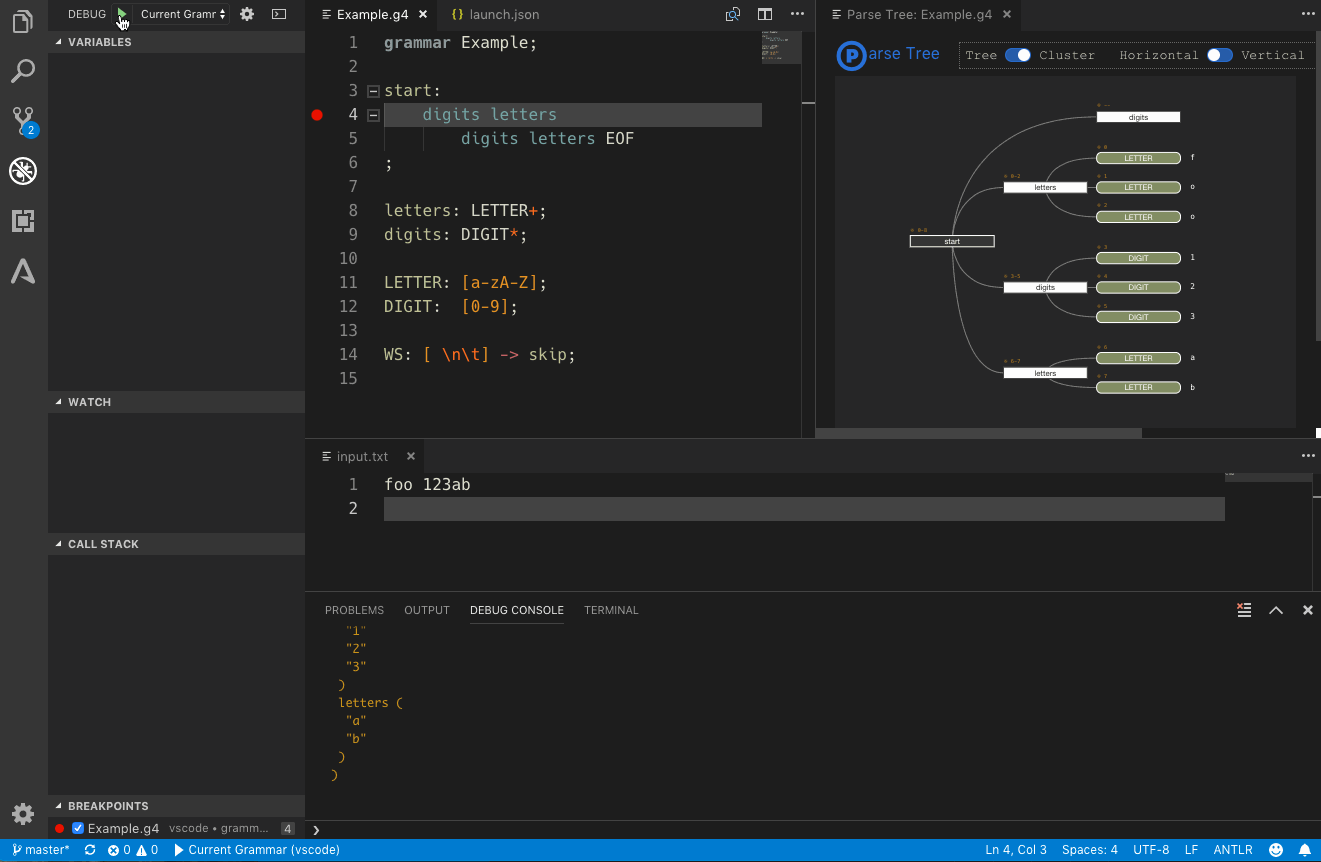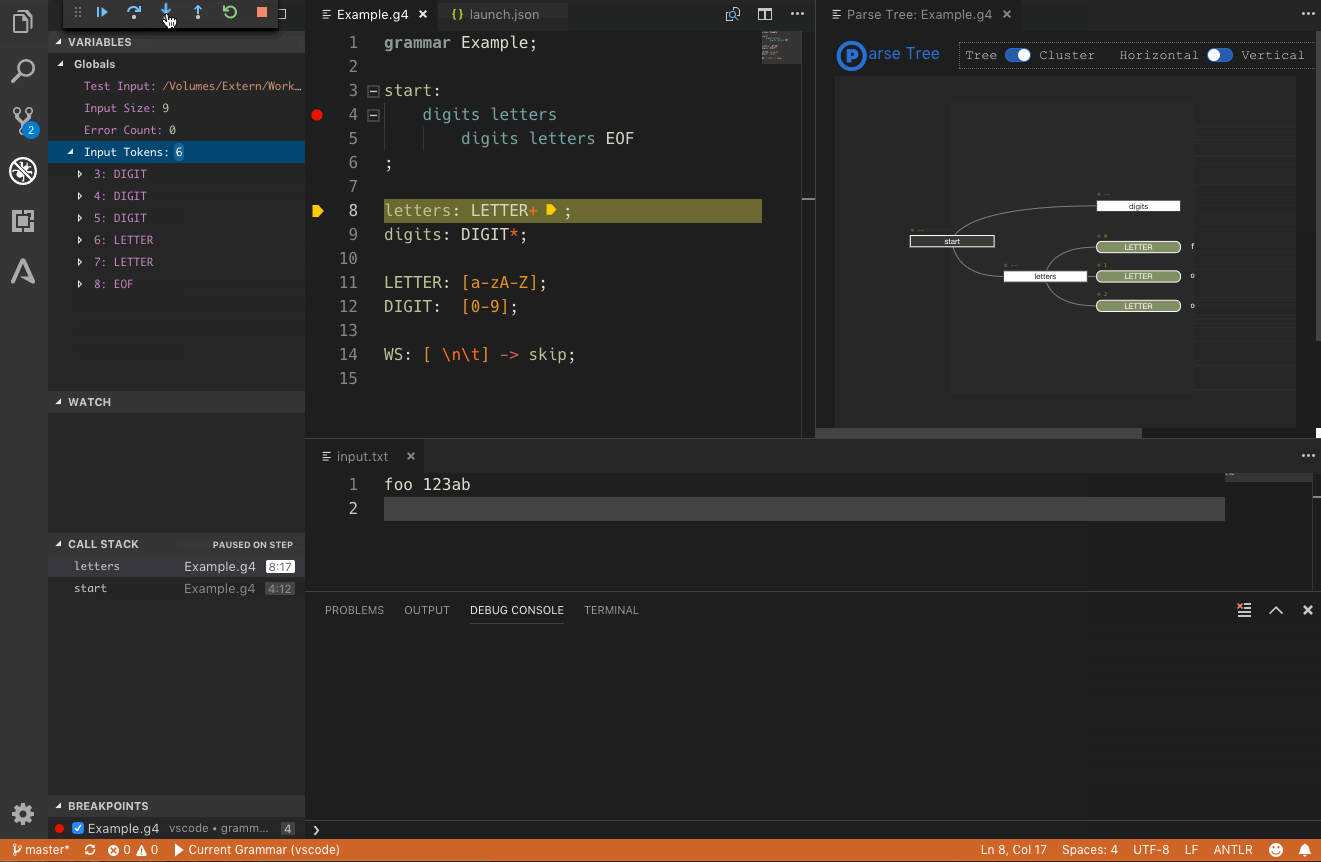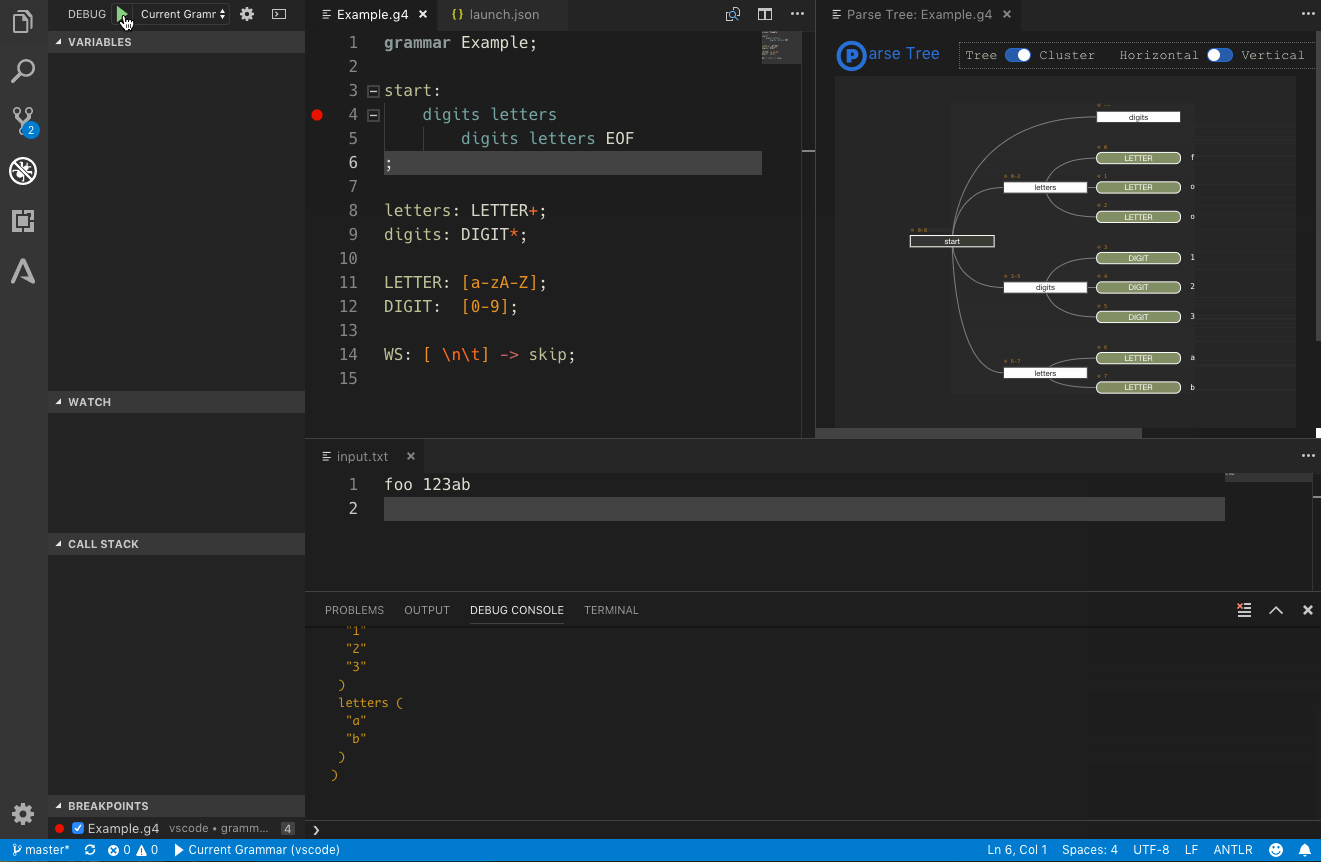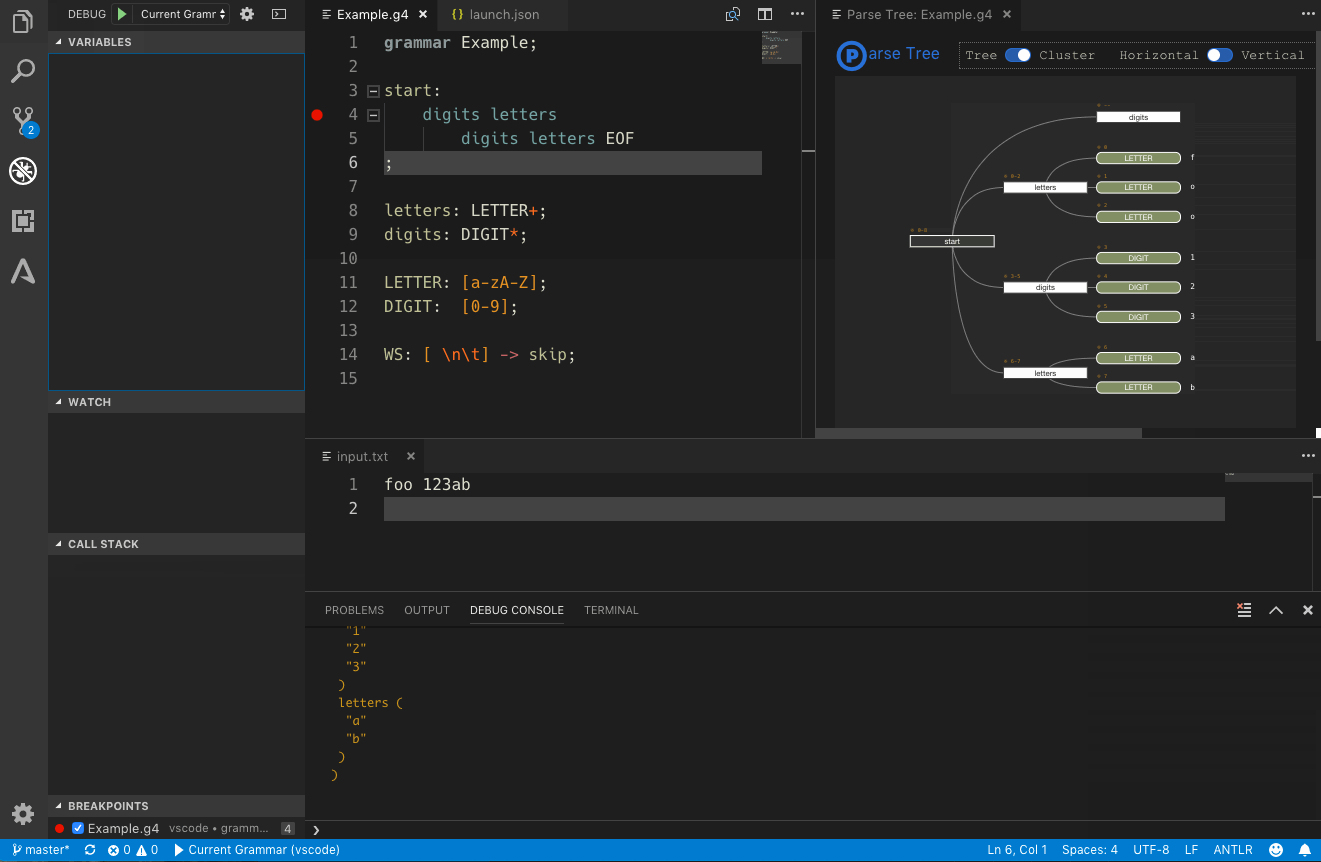
Last week another update of the ANTLR4 Visual Studio Code extension went out and now you can debug your grammars with it.
The extension supports debugging of grammar files (parser rules only). At least internal code generation must be enabled to allow debugging (which is the default and requires a usable Java installation). This implementation depends on the interpreter data export introduced in ANTLR4 4.7.1 (which is hence the lowest supported ANTLR4 version).
All of the usual operations are supported:
- Run w/o debugging – just run the parser interpreter (no profiling yet, though it’s planned)
- Run with debugging – run the interpreter and stop on breakpoints
- Step into parser rules
- Step over lexer tokens and parser rules
- Step out of the current parser rule
Once the entire input is parsed, the parse tree can be visualized, either in the debug console as text or as graphical output in an own editor tab. This is configurable in the launch task setup.
The graphical parse tree is interactive. You can collapse/expand parser rule nodes to hide/show tree parts. Both a horizontal and a vertical graph layout is supported and you can switch between the standard (compact) tree layout or the cluster layout, where all terminals are aligned at the bottom or on the right hand side (depending on the layout).
As with all graphs in this extension, you can export it to an svg file, along with custom or built-in CSS code to style the parse tree.
Breakpoints
Breakpoints can be set for rule enter and rule exit. Currently no intermediate lines are supported. Breakpoints set within a rule are moved automatically to the rule name line and act as rule enter breakpoints.
Debug Informations
During debugging a number of standard and extra views give you grammar details:
- Variables – a few global values like the used test input and its size, the current error count and the lexed input tokens.
- Call stack – the parser rule invocation stack.
- Breakpoints – rule enter + exit breakpoints.
- Lexer Tokens – a list of all defined lexer tokens, along with their assigned index.
- Parser Rules – a list of all defined parser rules, along with their assigned index.
- Lexer Modes – a list of all defined lexer modes (including the default mode).
- Token Channels – a list of used token channels (including predefined ones).
Debugging Setup
Everything needed for debugging is included (except Java, which must be installed on your box and be reachable without an explicit path). You only have to configure the launch task to start debugging. Here’s an example:
{
"version": "0.2.0",
"configurations": [
{
"name": "antlr4-mysql",
"type": "antlr-debug",
"request": "launch",
//"input": "${workspaceFolder}/${command:AskForTestInput}",
"input": "input.sql",
"grammar": "grammars/MySQLParser.g4",
"startRule": "query",
"printParseTree": true,
"visualParseTree": true
}
]
}
As usual, the configuration has a name and a type, as
well as a request type. Debugging a parser requires some sample input.
This is provided from an external file. You can either specify the name
of the file in the input parameter or let vscode ask you
for it (by using the outcommented variant). Everything else is optional.
If no grammar is specified, the file in the currently active editor is
used (provided it is an ANTLR4 grammar). The start rule allows to
specify any parser rule by name and allows so to parse full input as
well as just a subpart of a grammar. If not given the rule at index 0 is
used as starting point (which is the first rule found in your parser
grammar). The parse tree settings determine the output after the
debugger has ended (both are false by default).
Limitations
The debugger uses the lexer and parser interpreters found in the ANTLR4 runtime. These interpreters use the same prediction engine as the standard classes, but cannot execute any target runtime code. Hence it is not possible to execute actions or semantic predicates. If your parser depends on that, you will have to modify your grammar(s) to avoid the need for such code. There are however considerations about using an answer file or similar to fake the output of predicates.
The interpreters are implemented in Typescript and transpiled to Javascript, hence you shouldn’t expect high performance parsing from the debugger. However, it should be good enough for normal error search.
Even though ANTLR4 supports (direct) left recursive rules, their internal representation is totally different (they are converted to non-left-recursive rules). This makes it fairly difficult to match the currently executing ATN state to a concrete source position. Expect therefor non-optimal step marker visualization in such rules.
Parser rule context variables, parameters and return values cannot be inspected, as they don’t exist in the interpreter generated parse tree.